
ServeFlow
Fast-slow model architecture for network traffic analysis
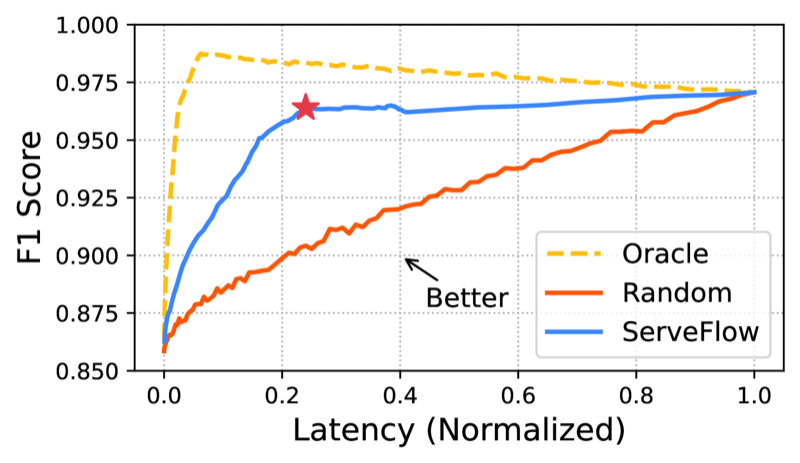
Overview
ServeFlow is a novel model serving architecture designed specifically for real-time network traffic analysis. It employs a fast-slow dual-model approach that intelligently balances minimal latency, high throughput, and accuracy to handle high-bandwidth network flows where data arrives faster than traditional model inference rates allow.
The Problem
Network traffic analysis faces unique challenges in ML model serving:
- Temporal Constraints: Flows arrive faster than model inference rates on high-bandwidth networks
- Real-Time Requirements: Individual flows have strict temporal constraints
- Scalability Limits: Traditional scale-out approaches used for other ML applications don’t work for network data
- Throughput vs. Accuracy: Must balance high service rates with classification accuracy
Model inference times vary dramatically (1.8x to 141.3x across models), and traditional approaches force a choice between speed and accuracy.
What ServeFlow Does
ServeFlow implements an intelligent dual-model serving system:
- Fast Model: Lightweight model handles the majority of flows quickly
- Slow Model: Computationally expensive model engages only when fast model predictions show insufficient confidence
- Adaptive Routing: Dynamically assigns flows based on uncertainty thresholds
- Optimized Timing: Leverages the insight that inter-packet waiting times exceed inference time by 6-8 orders of magnitude
Key Features
- Dual-Model Architecture: Fast-slow model design optimized for network traffic
- Confidence-Based Routing: Routes flows to slow model only when needed
- High Throughput: Processes over 48.5k new flows per second
- Low Latency: 76.3% of flows processed in under 16ms
- Accuracy Preservation: Maintains inference accuracy while improving service rates
Use Cases
- Real-time network traffic classification
- Intrusion detection systems
- Quality of Service (QoS) enforcement
- Network application identification
- High-speed traffic analysis
- Any network ML task with real-time constraints
Results
- 76.3% of flows processed in under 16 milliseconds
- 40.5x speedup in median end-to-end latency
- 48.5k+ flows/second service rate on a 16-core commodity CPU server
- Maintained accuracy while dramatically improving throughput
- Handles flows with thousands of features per flow efficiently
Architecture Insights
ServeFlow exploits the unique temporal characteristics of network traffic:
- Inter-packet arrival times significantly exceed model inference times
- Model performance variance is highly predictable
- Uncertainty-based routing enables optimal resource utilization
Resources
Citation
@article{liu2024serveflow,
title={ServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis},
author={Liu, Shinan and Shaowang, Ted and Wan, Gerry and Chae, Jeewon and Marques, Jonatas and Krishnan, Sanjay and Feamster, Nick},
journal={arXiv preprint arXiv:2402.03694},
year={2024}
}