
CATO
End-to-end optimization of ML traffic analysis pipelines
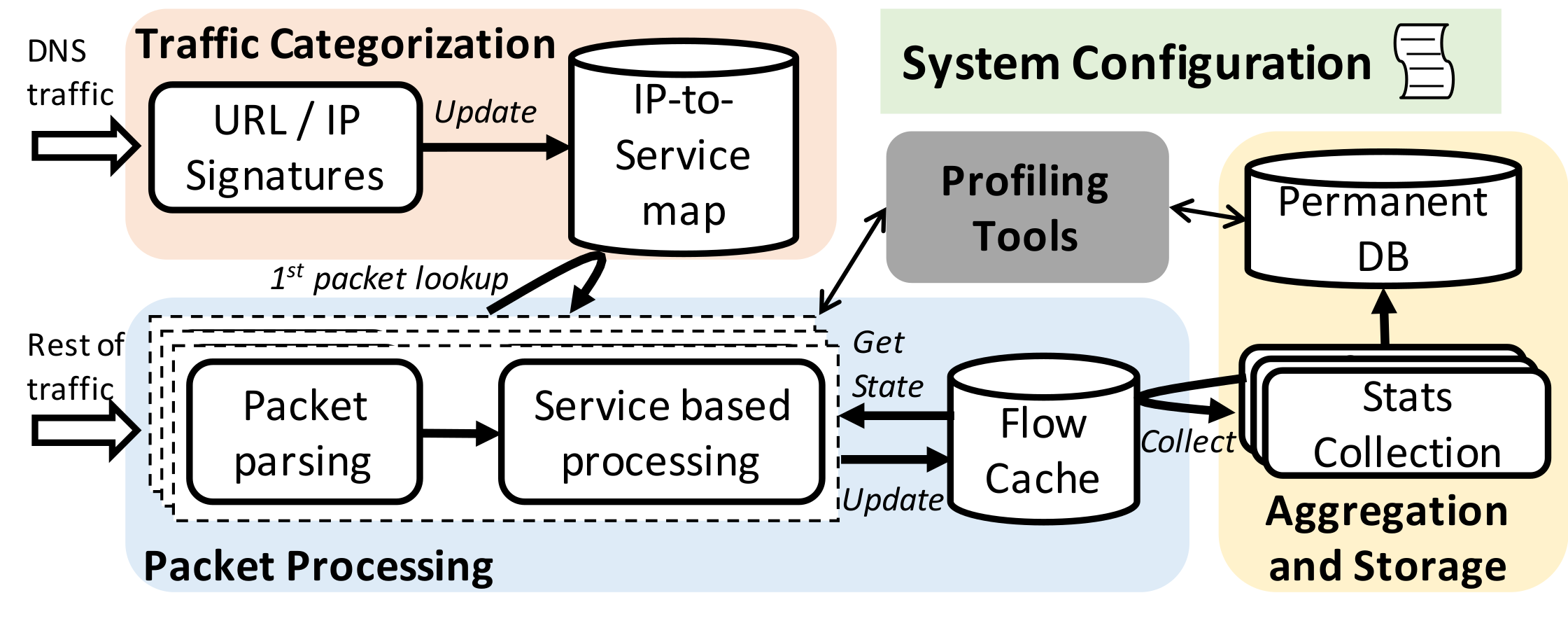
Overview
CATO jointly optimizes both the predictive performance and systems costs of ML-based traffic analysis serving pipelines.
The Problem
ML-based network analysis solutions often only optimize predictive performance, overlooking practical challenges of running models against network traffic in real-time. Efficiency of the serving pipeline is critical for usability.
How CATO Works
Uses multi-objective Bayesian optimization to efficiently identify Pareto-optimal configurations. Automatically compiles end-to-end optimized serving pipelines deployable in real networks.
CATO searches for optimal combinations of:
- Which network traffic features to analyze
- How much traffic data to collect before predictions
Results
Compared to popular feature optimization techniques:
- Up to 3600× lower inference latency (minutes to <0.1 seconds)
- 3.7× higher zero-loss throughput
- Better model performance simultaneously
Example: IoT device classification achieved better accuracy using just 3 packets vs. baseline approaches requiring 10 packets.
Resources
Citation
@article{wan2025cato,
title={CATO: End-to-end Optimization of ML Traffic Analysis Pipelines},
author={Wan, Gerry and Liu, Shinan and Bronzino, Francesco and Feamster, Nick and Durumeric, Zakir},
journal={USENIX Symposium on Networked Systems Design and Implementation},
year={2025}
}